Rethinking the role of communication in science
by Russ Hodge, copyright 2018
INTRODUCTION: FLYING WITHOUT A MODEL
Science communication is highly susceptible to phenomena I call “ghosts”: invisible, silent entities that interfere as we try to understand what someone means. Their effects are most obvious in conversations between scientists and the lay public, or discussions that cross disciplinary boundaries. But ghosts are a major irritation as young scientists try to write and speak effectively about their work. At later stages of a career their effects are usually more subtle but just as annoying, in disagreements between authors and reviewers and arguments over scientific models. And they even interject themselves into the inner dialogue between a scientist and the system he is studying, through hidden assumptions and other mental structures that shape perceptions and restrict choices in interpreting results. Exposing ghosts helps resolve misunderstandings by clarifying thinking in a way that can also improve the quality of a scientist’s work. And the best way to make a ghost visible is by trying to communicate a piece of science to someone else.
This concept has emerged from a long search to understand diverse problems in the communication of science: in my own work and that of others. Here I will refer mainly to writing, drawing on examples from texts, but the same issues arise in talks, schemes, animations, posters, mathematical models, and any other mode of representing and communicating scientific ideas. I will also refer mainly to molecular biology, but other areas of science face the same problems.
My main job for the last 20 years has been to write about cutting-edge discoveries in this field, mostly for a general audience, but increasingly for specialists as well. For someone with no formal training in the natural sciences, the learning curve has been constant, logarithmic – very steep. When I began my institute asked if I couldn’t also provide training in writing and presentation skills for the scientists. Even with a background in teaching writing, I quickly discovered a huge range of problems that I didn’t understand at all in the texts of my students.
I have mainly been teaching doctoral candidates or postdocs actively working in laboratories. Scientists have to write constantly – a thesis, papers, grants, and so on – mostly in English, not the native language of the majority of my students. Despite the fact that the quality of their writing is an important factor in getting papers published and getting jobs, this skill is almost entirely neglected in the curricula of university science programs across continental Europe. The last time most of my students did any writing was in a high school literature class, where the emphasis was on artistic uses of language rather than acquiring basic, functional communication skills. Graduate programs try to make up for this by hiring external teachers to do workshops, often within an optional program of “soft skills” courses including topics like leadership and ethics.
Many of these programs are not regarded highly by every head of a lab; some are reluctant to let their students attend. This usually limits the length of a workshop to two days (three is a real luxury) in which, by some magical process, I am supposed to help students develop a very complex skill which will profoundly influence their careers. It’s hard to work a miracle in that space of time – so the skepticism of scientists becomes a self-fulfilling prophesy.
I believe this situation reflects an ignorance of the real function of communication within science – or at least its potential function. This system is based on a flawed and vastly oversimplified view of the process of writing, of how scientists think, and of how these things interact. I don’t know any model of writing, teaching, learning, career preparation, or cognition that could possibly support the neglect of communication skills – but in these areas, when you speak of models, people look confused, as if such a thing has never occurred to them.
Science would be unthinkable without models, but for communication and education, universities and institutions seem to think they can do without. Their approach seems to have evolved without any consideration of its impact on students and their careers. Maybe that’s the model: a sort of natural selection in which organisms are left entirely on their own to sink or swim. Survival requires exceptional motivation, natural talent, or great luck in joining an exceptional lab where the group leader cares enough to train them.
The current state of affairs completely fails to understand the potential of writing as a path toward clearer thinking, as a powerful tool for teaching and learning, as a way of developing creative new approaches to scientific problems, and as a method that even has the potential to improve the quality of research.
* * * *
Writing is not a direct expression of thinking, but it can reveal interesting aspects of the cognitive organization of a writer’s mind. Initially, I made the naïve assumption that students’ deep knowledge of their topics would help them avoid problems in organizing content when they wrote. Instead, I found that their texts were tangled at every level: sentences, paragraphs, and larger functional units of texts. There were problems of clarity throughout, but when I tried to paraphrase sentences into a cleaner structure, I almost always distorted the scientific meaning. You can’t paraphrase someone if you don’t know what they mean. I was confronting a problem of thinking, and meaning, and matching ideas to language.
For the next few years I dealt with content as most of my colleagues do: by giving students tasks that resembled parts of scientific rhetoric – writing recipes, giving directions or other instructions. It’s satisfying to see them to do such exercises well – then you discover that this type of learning rarely transfered to real situations in which they wrote about their own scientific work. At that point everything seemed to fly out the window. This problem is well documented, and it left me stuck at a barrier that other teachers were quite familiar with: the only real alternative to exercises is for the teacher to immerse himself in extremely sophisticated content.
I have had fantastic teachers throughout my life, starting with my parents, who were both educators. We were the first to truly profit from a generation of instructors who were using the new models of learning and cognitive development that were emerging from psychology, linguistics and other fields. Fresh ideas were being implemented in the classroom bu also in alternative learning environments, using new methods that resembled play and performance, by a generation with strong ideals. My teachers knew they were not just passing along information, but trying to develop our understanding, and forming people as well. In their hands I experienced the art of teaching first-hand; it wasn’t until my own training to become a teacher much later that I realized the degree to which it is a science as well, and how what often seemed so natural was the result of hard, methodical work.
Teaching is a very pure form of communication because it is goal-oriented – the audience is supposed to learn something, and are usually tested in some way to measure learning in a process that often reveals more about teaching. To be effective, teaching has to resolve the major issues in functional communication. It is very likely to fail if the teacher doesn’t develop reasonable expectations about how students have their knowledge organized, or how they learn, or whether the content can be broken down into information, skills, and tasks that are actually learnable. If the message doesn’t get across, the first thing to do is articulate the problem as clearly as possible. Before I could help students develop a skill as cognitively complex as writing, I had to have a much better understanding of what I actually wanted them to do. What was wrong; what needed to change? As I read paper after paper, the concept of ghosts began to emerge as a model that could account for several types of content-related problems I was seeing over and over. A good model would have implications that could be tested in the laboratory of the classroom, producing results that could be fed back into the model to improve it.
Most teachers I know are well aware of the symptoms of ghosts and classify them in various ways: as a lack of clarity, failing to take the perspective of an audience, forgetting to link ideas in logical ways, or a general disorganization of thinking that spills over into writing. All of these issues have something to do with content, with putting ideas into words, and with the writer’s understanding that the knowledge of the person he is writing for may be organized in a different way. Not all of these problems stem from ghosts, but ghosts certainly manifest themselves in all of these ways.
Seeing their effects as symptoms of a deeper, unifying principle was a crucial step that not only suggested solutions, it began changing my reading habits. I had to try to fully understand the intent behind each sentence. I had to generate a hypothesis about what it was “truly trying to say;” when it was clearly awkward I had to distinguish between awkward language and muddled thinking. When I didn’t understand something, I forced myself to ask why. Ghosts began to emerge when I discovered how much of glue of logic and ideas that held scientific texts together was not actually contained in it, but lay beneath it, behind it, a structure only in the author’s head. I began seeing repetitive patterns in the missing connections. If a sentence appeared out of nowhere, I made a guess about the connection. If I found a gap in logic, I generated hypotheses about different ways it might be filled in. It felt like learning the principles of electronics by inheriting thousands of radios whose connections had come loose. This wire is disconnected, what should it hook up to? The fact that I could immediately check my guesses by talking to the student was a fantastic opportunity to learn very specific things about how scientists write and how they think – in a hypothesis-driven approach. My model was coming together.
“Ghosts” seemed an appropriate term for a type of problem that was disruptive because it was invisible – in other words, something was missing from a text. The problem is not simply the definition of all the terms – they can be looked up. If you know what question you have to ask to clarify a problem, you’re already most of the way toward solving it. Ghosts are something different; their “invisibility” refers to the difficulty of pinning them down.
Ghosts arise from any dimension of a message or situation that can confer meaning – in other words, from virtually any aspect of communication. The most common source of misunderstandings is a mismatch between the expectations of a writer and reader that works itself out in ways that are hidden, because essential concepts or connections are missing from the message itself. Anyone uninitiated who has tried to read a scientific paper is likely to have difficulties that go beyond single pieces of jargon, because such papers belong to a genre that reflects the communicative habits of a community, and it encodes sophisticated expectations that a reader needs to be aware of. There are also some rather unique aspects of the way science assigns meaning to things in science because it aims to describe systems in reproducible ways. Science would prefer the definitions in language to be more formal and digital, and to struggle less with ambiguity – just like it would prefer its technologies and the systems it studies to produce less noise, and our thoughts to be clearer or more rational. Some problems in communicating it arise from the fact that our minds and language just don’t quite work that way.
I realized I wasn’t working from any real model at all of the interplay between content and language – I had taken a lazy approach to distinguishing mental concepts from the words that tried to capture them.Building such a model would require a systematic analysis of students’ problems, and that would require an exacting analysis of the content they were trying to express. I spent almost four years on this, borrowing a strategy from the geneticists of the early 20th century. The most efficient way to discover the functions of a gene, they discovered, was to observe how they were disrupted through mutations. By analogy, problems in texts could shed light on how thinking and language come together in good writing.
The writing courses I was teaching gave me a laboratory to test every new concept that emerged from this work. If a problem could be articulated clearly enough, and if I could apply enough creativity, a didactic solution could be found. If an idea didn’t help I refined it or changed the underlying model I was building.
Ghosts were one of several ideas that began to profoundly change my own writing, my understanding of the process, and my view of scientific thinking. Ultimately this led to an entirely new perspective on the functions of communication in science.
* * * *
During the process of writing, if one intends to do it well, something happens that forces a researcher to reorganize his ideas a bit differently than normal, to think a little differently about science. Compromises have to be made. Some people struggle over sentences a long while because out there on the page it isn’t quite right – it isn’t as good as it ought to be. A text is written explicitly to be argued over, in hopes that the community will reach a consensus. Single scientists do not make the ultimate decision about how a biological process should be understood, any more than an individual determines the grammar of a language. A few brilliant researchers actually do achieve this, but they usually have to be exceptionally stubborn: sometimes their ideas languish for decades waiting for a field to catch up.
In writing about science an author is often trying to share an observation of a very specific type, to convince someone to think the way he does, or assign significance to things the way he does, or convince the audience that his interpretation of something as justified. The author has to own it, to accept this difficulty, to play out the consensus-reaching exercise in his head as he writes. This is how new scientific concepts and models form – whether the issue is a huge new theory such as evolution or the fine details of a biochemical signaling pathway in a cell. The extent to which a scientist understands what his colleagues mean depends on how he integrates their findings with his own knowledge, and this integration guides the way he preceives systems, formulates hypotheses, and reflects on results.
I needed to understand these processes to build a model of meaning in science, which was lacking in my analysis of students’ problems. Ghosts are an essential part of that model. This work is under the same constraints: it is a system of interlinked concepts which needs to undergo a similar process of evalutation and consensus by other teachers. The main aim of this text is to start a discussion with a broad community of scientists and communicators on how they cope with issues in writing and other types of science communication, in hopes of developing a more useful model. Comparing our experiences and the language through which we describe them will be essential in improving our teaching.
* * * * *
Ghosts are inherent to the constructive nature of knowledge and language
Ghosts are concepts or relationships which are essential in understanding something the way it is intended, but which are not articulated in a particular text (talk, image, etc.)
Every act of communication rests on a vast repertoire of the unspoken, particularly assumptions and expectations about how we use language to reach meaning. This makes ghosts inherent in language and other systems of representation.
We develop our concepts of the world and attach them to language in individual, constructive ways. Both my concepts and my names for things originate in experiences that are unique to me. Even when two people draw their information from the same text, or observe the same thing, they integrate it into the larger relational networks of meaning that an individual has to draw on. Our cognitive architecture “primes” us to understand things in distinct ways. Cells are similarly primed by their states and molecular composition, so an identical signal can trigger completely different responses in different cell types.
After abstracting concepts from experience and attaching language to them, I generalize them in two ways: grouping objects that aren’t significantly different from each other into the same category, and identifying new objects I encounter as belonging to it or not. Over time social interactions shape our use of words and the also the concepts they refer to, but there is a “resolution limit” to these corrective processes. Once a group agrees on the meaning of a word – to the extent that they reach a functional agreement on the two types of generalization – we don’t have to go further. Beyond that point, differences in what things mean will be regarded as individual connotations.
Both neuroscience and psychology support these constructivist views of knowledge and language and the limitations they impose on communication: There is only a certain extent to which we can be sure that something means the same thing to different people. But the natural sciences don’t have to be happy about it – their claims depend on an ability to agree on meaning in a way that surpasses traditional linguistic boundaries – ideally to some ultimate “atomic” or “molecular” level of meaning. The core scientific principle that experiments should be reproducible requires that experiments be described in a way that permits reproduction, and that the objects and systems under study can be understood in an unambiguous way by scientists in the field. The latter condition led to a huge effort over most of the 20th century to develop strains of model organisms that were as homogeneous and standardized as possible and share them between labs – as a means of removing sample bias and eliminating noise. In other words, as a way of ensuring that the same things would happen and that they meant the same things in different places.
In practice, most experiments are never reproduced in a second laboratory. To do so would require that a group devote significant time and resources “just” to check the work of other groups. In some cases attempts are made but fail, and this usually sets off a discussion as to why. Eliminating instances of outright fraud in the original paper, the difference may be due to a technical error by one of the labs, or some sort of bias in the sample. But sometimes the original group will claim that it took great time and care to set up an extremely delicate experimental system, and the second lab has failed to take everything into account, or they have failed to follow a protocol precisely enough – when the second lab says that it has. This is essentially a claim that the two labs do not agree on the meaning of the text that one of them has written. A gaff in the writing? An oversight in the reading? Or is language simply not precise enough to capture every aspect of an experimental environment that might play a role in the outcome? Whether or not reproducibility is achieved, even to aim for it places unusual constraints on the way language is used in science.
The language used to describe experimental procedures is descriptive; another type of constraint on language comes into play when scientists interpret the outcomes of their experiments. Here the issues are thinking, logic, and a particular type of reasoning in which a range of current scientific models are in dialogue with the system that is being studied.
Normally in the Results and Discussion sections of a paper, scientists try to explain the meaning of the outcomes of experiments in relation to an initial question raised in the paper. The meaning of this question, in turn, has to do with the scientific models it relates to. These models are so central to the issue of ghosts that I will be explore them in depth in the next sections.
* * * * *
To be judged a competent scientist, it is not enough to grasp the meaning of the individual words that other scientists use, or to arrange them in grammatical sentences. Being a “native speaker” of science goes beyond this, and a study of ghosts reveals aspects of scientific meaning that are quite profound.
By definition, as stated above, a ghost doesn’t appear in the specific context in which it is needed to clarify meaning. One problem in science is that some ghosts are almost omnipresent because they are almost never directly stated. They may lie within the “fabric” of a field: they are encoded in a collapsed form into the meaning of many of its central concepts, but these terms or practices may be such common currency that their meaning is accepted without often being explicitly deconstructed.
The most important result of this project has been to clarify the relationship between ghosts and scientific models. Scientific work requires researchers to draw on all sorts of concepts, definitions and patterns to describe biological systems, make predictions about their behavior, and interpret experimental results. Most of the concepts a scientist will draw on are already “out there” in some form; he is primed by layers of models, their constant correction or refinement through experimental data, a new layer. Everything is constantly being revised, at large levels and small, and as a scientist works in a tiny little system he is also working in much larger ones; by doing some one small thing, he may obtain results that challenge the entire apparatus. Everything that happens is shared by learning, and the challenge is to integrate it into wider types of knowledge. These negotiations often happen outside of our direct awareness; we are constantly making associations and applying metaphors without being aware of it. Scientific models contain patterns that arise from more basic modes of understanding, are highly metaphorical and maintain a degree of abstract flexibility in the mental laboratory.
I’ll try to illustrate this with a simple example. Biologists talk all the time about proteins binding to each other and the chemical events that take place when this occurs. A chemist or structural biologist sees this binding as a series of tinier steps by which bonds between specific atoms are altered and rearranged, and a stage-wise progression of events involving movements within a molecule that pass substances from one configuration to another, all in accordance with detailed chemical and physical patterns. Someone who doesn’t know all the details can still work with it by understanding the process more basically, as a process of attachment, movement, transfer, and release. Even more generally: things become attached and passed from one to another. At a very human level of experience: we touch someone and give them something. These are all ways of seeing the same thing. None precisely reflects reality in all its detail; all are governed by cognitive patterns that we learned long ago and have revised to the level of detail we need.
Models establish patterns and a logic by which single findings can also be linked to the vast frameworks of theories such as evolution and fundamental rules of physics and chemistry. In one way or another, these patterns are imprinted on the meaning of nearly every word and idea in a scientific text, but most of them aren’t directly articulated in it. Scientists are so used to this style of creating meaning that they may not consciously realize how many such patterns are there, and even those they are aware of will only appear in shorthand in the texts they write. There is an important exception to this: a single paper or project is almost always in a rather direct dialogue with an existing model: testing it, enhancing it, transferring it to something new, or refuting it, and its meaning will be interpreted in relation to this dialogue. The connection between a question and the models that generated it, at least, ought to be articulated in the paper.
So models shape the meaning of a scientific article in powerful and complicated ways while remaining mostly invisible, and precisely this invisibility is a huge challenge as students learn science and learn to write about it. In a way it’s like trying to master a language without being taught its grammar in any systematic way. The same issues, obviously, enter into communication with non-scientists in a more general form. The concept of ghosts is extremely useful to scientists in planning a piece of writing or talk, to students as they learn to do so, and to non-scientists when they approach research – by showing them where to look for meaning and how to best give a statement the context it needs to build meaning that we can agree on.
In the following sections I will give some examples of various types of ghosts, with remarks on their implications. As stated above, identifying a ghost does more than explain a communication problem; it often says something profound about scientific thinking by exposing a hidden structure that lies behind it and justifies it. That’s useful not only for a reader trying to unravel the meaning of an abstruse text, but also for a scientist engaged in the highly complicated process of clearly formulating thoughts and trying to find the best language to express them in.
1. Ghosts in names: what is NFkB?
Single words and the names of objects and processes in science often derive their meaning through the vast, ghostly collection of models they are linked to. I’ll demonstrate this with the name of a gene called NFkB (pronounced “N – F – kappa – B”), which will reappear in later examples. The initials stand for “nuclear factor kappa-light-chain-enhancer of activated B cells,” in case you’re interested.
The ways scientists use the names of genes and other types of molecules reflect historical limitations in the types of methods and experiments that have been available to explore the molecular scale of life. Until very recently, nearly every method used to identify and describe a molecule required millions or billions of copies of it. A protein, for example, usually had to be extracted from its normal environment and studied under fairly unusual conditions. Such experiments provided a statistical readout of the molecule from which the features of individuals could be derived. This procedure suffered from the same basic type of problem you would have if you tried to make guesses about an individual person from census data.
As a result, in practice NFkB is almost never truly used to refer to a single, specific molecule – at least not the way “chair” can be used to refer to a quite specific chair in a room, although it often sounds that way when scientists talk or write about it. It’s more of a floating concept that can be applied to many objects, sometimes even when collecting objects from clearly different categories into a lumped term.
An analogy might be a line at the passport control station of an international airport. When coming into Germany there used to be a line for “Germans”, another for “EU” and a third for “Other”. Everyone who successfully makes it past the German booth is a German, even though many distinct individuals fit the bill. The only thing the people in the line have in common is that they have a German passport, and from this you can infer they fit certain requirements for citizenship – in other words, you link it to certain types of mental models that distinguish its appropriate use from improper ones. In language, the word “German” is linked into a network of concepts related to nationality, citizenship, parentage and so on. But if you didn’t see the last person to come through the control booth, you wouldn’t be able to say whether the person had been a male or female or child, or much of anything else about them. You could make a statistical prediction, but not much more.
In a similar way, NFkB describes many objects that meet certain criteria, but there is no one representative example, and a scientist may never know exactly which of the possible variants is meant in a particular context. All you know is that the object meets the “citizenship criteria” of belonging to NFkB.
Things get more complicated because the same name is applied to three fundamentally different types of molecules: DNA RNA, or protein. If you’re talking about a gene, then you’re referring to a sequence in a cell’s DNA that best matches a sort of generic NFkB sequence (within certain statistical limits) which is a big abstract concept. The other two forms are derived from their chemical relationship to each other. If the object is an RNA, it has been transcribed from the NFkB gene, and a protein has been translated from the RNA.
It’s possible to determine the precise sequence of each of these molecules in a specific cell. The gene occupies a region that is well over 100,000 bases of the DNA sequence in length, and we know where it ought to be and some spellings that tell us exactly where it begins. The RNA that is transcribed from it will only use fragments of this and have far fewer bases, but its sequence can similarly be determined by clearly distinguishing its spelling from other RNAs. The protein made from the RNA will only have one third (at most) of that number of amino acids. But there is no objective definition of the molecule because its sequence is likely to vary by a few letters in every individual person. In practice, that’s not necessary: you just need to distinguish NFkB protein from every other protein encoded in a different gene, and likewise for the RNA.
So when a scientist plans an experiment involving NFkB, he is not thinking about a “real” specific NFkB – he could never recite the 100,000 letters of the sequence by heart – but rather a concept of the molecule. He has taken this concept into a mental laboratory as a sort of metaphor, where everything else is a concept and sort of metaphor as well. His concept of NFkB is even more abstract than an archetype representing all the variations in individuals, because the same name is given to genes in different species as well. Their sequences vary even more widely. This is called “homology”, a concept which derives its meaning from the major premises of evolution.
The reason scientists are comfortable with giving the same name to cells of humans and mice lies in the fact that humans and mice inherited the gene from a common ancestor in the distant evolutionary past. The version these species have now have changed from the ancestral form through mutations and selection, but are still similar enough that their relationship is evident. They have many of the same functions in diverse cells of the two species. So “homology” refers to similarities either in the form or function (usually both, to a certain degree) of two specific components or features found in two species that derive from a single instance in their common ancestor.
A sophisticated extension of the concept of homology is the use of model organisms to shed light on each other or on humans – which is only successful because the vast majority of their molecules (and tissues and bodily structures) are homologous. Sometimes scientists speak of a molecule and its functions without referring to a species at all. Sometimes in a paper involving mice and humans, a reader loses track of which species they are referring to at any given moment, and sometimes it’s hard to determine whether they are talking about a gene, RNA or protein. There are conventions for doing so – using capitals, or italics – but the conventions differ in communities working on flies, fish, humans… In those cases it presumably doesn’t matter very much, because it’s the concept of NFkB that counts, and not the particular example.
If you find all of this somewhat maddening, you’re not alone, and it’s not the only thing in molecular biology that can be maddening.
The point is that these habits of classification, abstraction and naming only correspond to a certain degree to our usual linguistic habits. What a scientist means with the term NFkB overlaps with the way we refer to objects such as “chairs” in our daily lives, but it is not the same because names for molecules and other scientific concepts are loaded with ghosts. In this case of a “simple name,” the ghosts reflect scientific models from chemistry, cell biology, genetics, and evolution, and we won’t fully understand what a scientist means when he uses the term unless we are aware of these ghostly dimensions.
Below I have used a “concept map” to visualize this description of the scientific models that govern the use of the label NFkB and determine its meaning:
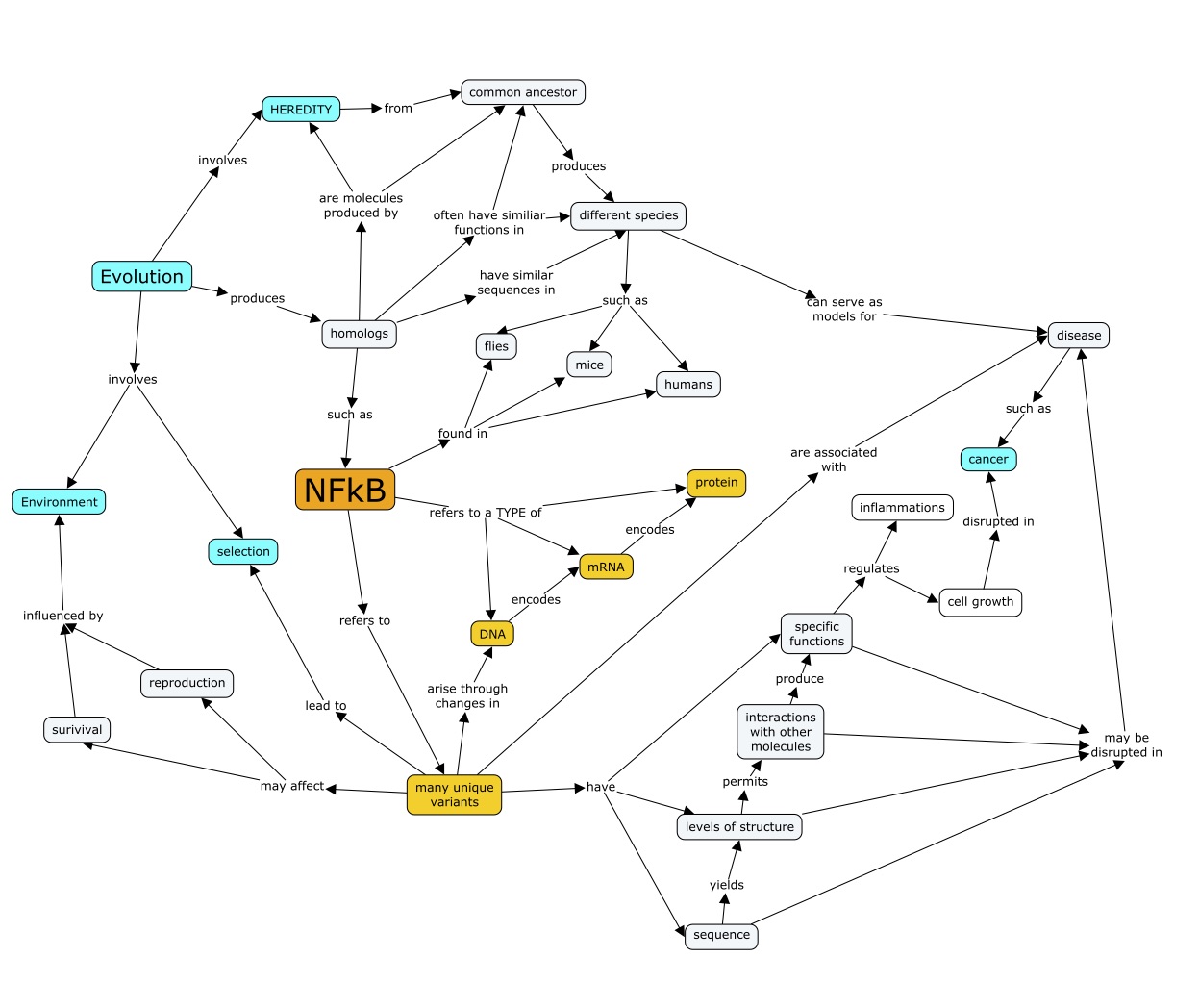
A “concept map” of the scientific models that lend meaning to the name of a molecule: NFkB
This invisible web of connectivity poses a huge challenge for students as they try to learn to write like experts in a field – because you’ll never find it laid out this way in the texts they read. Generally they have to build this structure in their own heads and properly position NFkB within it. At some point those who succeed will have internalized something like my personal structure, presented above; they will have built their own version of it in their minds. Having this structure doesn’t necessarily mean they will write about it well, but not having it will make it almost impossible for them to do so. It is extremely difficult to write clearly and intelligently about something which is highly chaotic in one’s head. Any confusion regarding the position of NFkB in relation to these scientific models is very likely to appear in their writing.
This leads to a crucial point: How can you tell whether someone has truly organized his knowledge the way scientists do, and has digested this hidden “grammar” of science? The best way is to look at his writing. The structure of a person’s knowledge guides the organization of ideas in a text and the structure of arguments. If a student has serious misconceptions, writing usually reveals them through a lack of clarity, inconsistencies, or flaws in argumentation. This makes a text, which is created through a process of breaking down meaning into a linear form, the best way to interrogate the architecture of a student’s knowledge.
* * * * *
2. Ghosts in missing or mismatched concepts: “What is a membrane like?”
Once you encounter a ghost and recognize it as such, you begin seeing them everywhere. Because I entered the field of science communication virtually overnight, with no formal training in the natural sciences, ghosts lay strewn about like land mines. I constantly felt their effects without being able to put a name to them.
One of the first stories I had to cover concerned the a study involving a new type of microscope and a question about cell membranes. One of the scientists in our institute had built his entire career around a hypothesis on substructures on the surfaces of cells. He claimed that as some proteins are synthesized within a cell, they are clustered with fat molecules, glued together by cholesterol. They form structures like “rafts” – the technical term is sphingolipid rafts – and are shipped as units to the plasma membrane surrounding the cell. In many cases diverse proteins – or several copies of a single molecule – need to work together to receive a signal on the cell surface or carry out some other function. Rafts would give the cell a way to prefabricate these ensembles. But at the time, there had been no direct proof that they existed, or how many proteins they might contain.
The scientists at my institute had attached a nano-sized bead to a protein in a cell membrane that was thought to belong to a raft. The new microscope permitted them to capture the bead in a laser and pull it through the membrane. As this happened, the amount of force needed to drag the bead could be measured very precisely. One of the scientists compared the process to catching a fish with a rod and reel: the larger the fish you have hooked, the harder it is to reel it in. By analogy, the larger the raft, the more proteins it could contain, and the more force would be required to move it using the laser. While the fishing metaphor helped immensely for a Kansas boy, there was something about the story I couldn’t quite grasp. I kept pestering the scientists with questions, and finally we figured out the problem.
It had been 20 years since my last biology class, in high school, and the only image I had of a membrane was a thick black line drawn around a cell. A line seemed like a solid, wall-like structure – and a wall wasn’t like a body of water – so how could you drag a fish through it? No, my colleagues explained – a membrane is more like two soap bubbles, one packed tightly inside the other. It’s more of a liquid that things float around in – think of the proteins as particles of dust.
I hadn’t understood the story because of a ghost: a conflict between my concept of a membrane and theirs. I lacked the image or model of a membrane that the scientists had in their heads. It doesn’t matter that the problem lay with me – that my concept of a membrane was completely wrong. The point is that knowing “what a membrane was like” was essential to understanding the story. But the scientists never explained it while telling their story. A membrane is so basic to biology that they all know it, and at some point they start to assume that everyone else knows it. And things that everyone knows – or is presumed to know – are rarely articulated.
Often these central concepts turn out to be the most essential in grasping the meaning of a piece of science. But there’s another problem: when scientists did bother to explain, they’d usually give a definition like, “The plasma membrane is composed of a lipid bilayer containing proteins and their aggregates, forming a barrier that breaks what would otherwise be a gradient between intracellular chemistry and that of the environment.” Scientists often define things in order to make them more precise, rather than to translate them into more general terms. Anyone capable of understanding this definition almost certainly already knows what a membrane is like.
The problem was finally solved through a metaphor, and this experience illuminated some common features of ghosts. First, they are often so basic that no one thinks of explaining them. Secondly, they often have more to do with “seeing what is in a scientist’s head” than having a specific piece of information. One way of achieving this is through metaphors, which can be powerful tools to resolve ghosts because they relate concepts to similar networks of meaning in two people’s heads.
* * * * *
Interlude: The inner laboratory
This story and many more like it revealed a point that was crucial for a complete novice to science to grasp. With very few exceptions, single proteins are too small to be clearly seen even with the most powerful electron microscopes. Scientists determine the chemistry, shapes and functions of single molecules from experiments based on enormous populations – often at least millions – of molecules. But you’d never guess this from the way researchers talk about a molecule they are interested in. It’s as if they are watching single objects moving about and interacting in a film running in their heads.
In fact, they are. Scientists use experiments to construct mental models of the components of systems and their interactions that are often highly complex and very detailed. Then in their minds they manipulate these systems – not real cells or molecules but conceptual representations of these things – in the space of a cognitive laboratory. They build this inner lab based on what they have learned from textbooks and classic papers, what they have been taught and what they have read and done themselves. They use it to run through scenarios in which they imagine the potential outcomes of experiments before deciding to commit time and money to carrying them out in a real laboratory. Usually the questions they pose arise from their cognitive models of a system, often by placing themselves at different points within it and imagining how things appear when perspectives shift, or applying various patterns to see which one fits best.
Sometimes scientists think through potential results of experiments the way a grand master of chess envisions a flowchart of moves, responses and outcomes. The difference is that no matter how well a system is understood, the response to a move may be unpredictable, seem fully unrational, demonstrate that there are pieces on the board that one hasn’t known are there, or even expand the board into entirely new dimensions. An experiment does not test only one model, even if that was what it was designed for – it tests every model that it is linked into. It may challenge many levels of models embedded in each other, and if results are unexpected, the question is to determine at what level in a hierarchy of concepts an assumption has been challenged.
To fully understand what a scientist means often requires not only developing very similar concepts, but also seeing a system as nearly as one can to the way it appears in his head. I had to gain as much access as I could to this inner world of concepts, rules and models. I had to create an inner laboratory of my own, listen to what they said, and try to figure out how I had to adjust mine to fit theirs.
This metaphor of chess is useful because it reveals something else: the average player can think a move or two ahead, perhaps; grand masters can play entire games in their minds. But as far as I know, they all start using a physical board. Imagine trying to learn the game merely from thousands of records of previous matches, using a notational system beginning with codes such as P-K4 P-K4 N-B3, without knowing what physical system they referred to. Would one ever be able to reconstruct that system, or the sense of the game? Especially since the “goal” – the last move – never appears?
I have no answer except to say it would be a fascinating exercise. The numbers attached to moves would always remain between 1 and 8, hinting at a spatial dimension in one direction, but this notational system assigns no numbers in the lateral direction. As for the letters, some refer to 8 functionally identical pieces per side, others to two, others to only one. It would be an incredible feat just to deduce how many of each type of piece was on the board – and you might not be able to do it without simultaneously concluding that the width of the board was also restricted to 8 squares.
If this task is so complex in describing a physical system in a finite space, what is it like for a scientist – where the spaces are many thousands of times smaller, but infinitely more complex? Where is the “board” on which science is played? What are the rules? One way of thinking of texts, images, and the other forms of communicating science is as records of individual games, played in the physical world of organisms and laboratories, but also in the mental world of models where explanations are developed, and the meaning of results explored.
Language can only reach into this cognitive space to a certain degree. While we grasp at our mental world with language, words are at best a translation of mental processes. Differences in our concepts and inner laboratories may be impossible to capture verbally, in images or any other form – but failing to realize that this is important is a significant source of ghosts.
* * * * *
3. Ghosts in missing models
The following text was produced as a press release on a scientific paper published several years ago. The intended audience was journalists and presumably the general public. Newspapers and magazines had gone through a phase of cutting the number of science journalists and editors they employed, so the best way to get something in a newspaper was to produce something ready-made for public consumption. The effort didn’t always succeed.
Rewrite the textbooks: transcription is bidirectional
Genes that contain instructions for making proteins make up less than 2% of the human genome. Yet for unknown reasons, most of our DNA is transcribed into RNA. The same is true for many other organisms that are easier to study than humans. Researchers have now unravelled how yeast generates its transcripts and have come a step closer to understanding their function. The study redefines the concept of promoters [the start sites of transcription], contradicting the established notion that they support transcription in one direction only. The results are also representative of transcription in humans.
Scientists often understand this text without seeing any of the potential ghosts, for an important reason. Because they share an a common architecture of concepts with the author, they relate each piece of information in a similar network and easily grasp its logic. Revealing the ghosts requires going through it carefully, sentence-by-sentence, and asking very basic questions:
What connects the first sentence to the second?
Genes that contain instructions for making proteins make up less than 2% of the human genome. Yet for unknown reasons, most of our DNA is transcribed into RNA.
What internal clues tell the reader how to relate the content of these two statements? Most readers will have heard enough about the genome and genes to associate them with the DNA in the second sentence. But a careful reading shows that there isn’t an explicit link in the text itself. What’s missing is one of the most fundamental models in today’s science:
DNA makes RNA makes proteins.
In 1958, when Francis Crick made this statement, it was bold and profound. Bold because it hadn’t been proven; profound because it suggested that the three major types of molecules in a cell were functionally related. This was important because it linked the hereditary material in a cell to its form and function. DNA is what we inherit from our parents, but how does that single cell they pass down to us build a body that resembles those of our parents? It accomplishes this by drawing on the collection of genes to produce RNA molecules and proteins. The press release assumes that readers are familiar with this model and can make sense of the word “transcribed into.” In practice, often neither is the case.
The phrase “Yet for unknown reasons” is interesting because it implies that readers not only are familiar with the model, but know something about about changes in the model over the past few decades. Originally DNA’s sole function was thought to be to encode proteins. Over time, most strikingly with the completion of the human genome, the “coding regions” were found to make up only a tiny fraction of DNA. If you don’t expect that to be the case – which scientists don’t anymore (because they know better), and nor do most other people (because they don’t know better) – the sentence becomes mysterious. It creates a red herring; some expectation has been violated (“Yet for unknown reasons”) and the uninformed reader won’t know what it is.
Some readers will interpret this second sentence to mean that the goal of the scientific project – and what the article sets out to explain – is to make those “unknown reasons” known. If that happens, they may miss the whole point, because the question – and the new thing that has been discovered – hasn’t been introduced yet.
The problems with the text continue into the third sentence. A reader may have trouble figuring out what “the same” refers to – the figure 2%, or transcription, or both? The fourth sentence poses additional mysteries.
“Researchers have now unravelled how yeast generates its transcripts and have come a step closer to understanding their function.”
Here a reader must make some assumptions based on word forms and grammar: if RNA “is transcribed” then presumably “generates its transcripts” means “makes RNA molecules…” But this is precisely the type of thing a reader unfamiliar with science is often wary of guessing – too often you guess wrong. To get the point the reader has to make an effort to construct a link between two ideas that isn’t explicitly there. Here the link is the ghost.
Secondly, the writer has shifted from introducing a fact – that human cells do something strange, which hasn’t been explained – to a mechanism: the focus is now on HOW this happens. The “how” question will be the central theme of this article, but is that clear? The “now” is linguistically ambiguous, because it might also mean “by now” and refer to some other piece of science in the past.
In fact this is the first sentence that broaches the real topic of the article, although the reader may not realize it because he is still be focused on the “unknown reasons” in the second sentence. That, in fact, turns out just to be a random fact on the side. The real story is the discovery of a new part of the process by which cells transcribe DNA into RNA. The two topics are vaguely connected, because the molecules that are produced in this new way happen to be “noncoding” RNAs. Here, too, this connection is never explicitly addressed in the article. Linguistically, the sentence lacks the typical markers or emphatic structures that signal “Here’s the major point; here’s the question behind the whole thing.”
To the reader, the sudden jump from a situation in human cells to yeast is unmotivated – there are no transitions to show the logic of how two ideas should be connected. That won’t matter to scientists, because they all instantly fill in what is missing exactly the way the author’s mind did: Yeast and humans are related through evolution, so by studying this simpler organism we can learn things about our own biology. This connection would be easy to fill in: “Using yeast cells, whose basic biology is similar to that of humans,” or, “In yeast cells, frequently used as a model to explore fundamental aspects of biology,” and so on.
Finally, the word “function” has a particular meaning in biology that will probably be obscure to most readers. What the writer is trying to say is, “The cell makes a lot of these RNA molecules that don’t encode proteins, so they must be doing something – but what?” And the use of the singular form of “their function” rather than the more linguistically typical “their functions” is simply a bizarre artifact of a past era in biology.
Scientists used to assume that “one molecule has one function.” That turns out almost never to be the case, and while they all know it, the singular form is still commonly used in this situation. The phrasing of the sentence is also ambiguous: a reader will almost certainly conclude that all of these extra RNA molecules have one and the same function (not true) or at the limit, that a single RNA molecule has only one function (also not necessarily true). This is a case where scientific language is stuck in a certain form while a concept has moved on. There are many such cases where knowledge has drifted farther than language – a point which will be covered below.
The next sentence potentially generates even more confusion by introducing a new term (“promoters”) and defining it as “start sites of transcription,” which is now to invite readers to create a visual image of a process in their minds. I’ll discuss this image-forming function of texts later, but it’s important to note that the reader hasn’t been given a basic image to start building on: “Imagine DNA as a string of text with individual letters. Certain codes in the string tell a machine of molecules where to land or dock on.”
If the reader is given this basic image, now a metaphor can be used to build on it. In this case the metaphor is reading and writing. DNA is “read” in one direction, and each letter of its sequence is used to write a new sequence in the chemical language of RNA, etc. And the definition of a promoter is given in the most confusing way possible: by showing its relationship to a model, which will be new to most readers (which the author expects – it’s why he has defined it) but then immediately retracting the model!
“The study redefines the concept of promoters… contradicting the established notion…”
Here is the sentence that actually tells what the scientists discovered, but this central point is only made indirectly, and is relegated to a phrase that masks its importance: “contradicting the established notion that they support transcription in one direction only.” How much nicer it would be to the reader to phrase the discovery as a positive finding (rather than a refutation of a previous model!): “proving that machines which land at this point can read DNA in both directions and write an RNA molecule in reverse order.”
This is the heart of the new discovery: Cells contain a machine that docks onto a DNA molecule and reads the chemical letters of its sequence to build a similar molecule called RNA. Until now, scientists have thought that when the machine lands it can only read in one direction – a bit like the way that English should be read from left to right. But now they know that the machine can also read the sequence backwards, and write two RNAs whose letters run in opposite directions.”
To sum up: What is wrong with this piece? It is full of ghosts – assumptions about a reader’s knowledge that will not be appropriate for a large part of the intended audience. A reader may not know what to ask to resolve problems in understanding its meaning. What’s missing isn’t simply definitions of terms, but a model of the way the ideas in the piece are connected. There is extra information that will be confusing, because making sense of it requires knowing scientific models that aren’t explained in the text, and a bit of knowledge about how those models have changed over the past 60 years. Scientists know those things, and that’s what’s in the back of their minds as they write texts like this. To recover what they mean, you have to know these things – but they don’t appear anywhere in the text in a form that can be recovered. They are ghosts.
What the writer of this article failed to do was first to conceive a very simple version of the main story to be told, and also to develop a reasonable hypothesis about what the intended readers were likely to know and what they were not. Ultimately you want the reader to go out with a small, connected story that makes sense – not just a list of facts. A reader could repeat every word in the text, even memorize it (forwards and backwards!) and still not understand it. Because the meaning of this story comes from an architecture of relationships between ideas that scientists refer to as models.
This text was written for a very general audience, but scientists who haven’t written very much have exactly the same type of problem when they are communicating with each other. In learning science they, too, have had to make sense out of lots of texts riddled with ghosts. If during this process they are highly aware of the fact that there are structures behind the links between thoughts, and actively look for them by trying to resolve what otherwise seem like jumps in logic or ideas that are out of place, they will read differently, and will hopefully write differently. They will know what to ask – or at least where to look for the pertinant question – when they don’t understand what they have read. When that happens you should always suspect that there is a ghost at work, and it usually has something to do with models.
This example shows that meaning in science derives from underlying models, which often lie at the hidden level of ghosts. Those models often go without explicit mention – so how do you know whether a student has mastered the models in his field? The only way I know is through a careful analysis of his texts or other types of communication. If the student is unclear about a model, or how it links to even larger models (examples below), there will be the same types of problems with the structure of his text as we found here. The details will be different, but the problem is fundamentally the same.
This means that to write like a scientist, a student has to think about models the way a scientist does. And if that thinking is unclear, it will inevitably be reflected in his writing.
* * * * *
Interlude: Other ways of representing the architecture of scientific ideas
What a writer means in a sentence is more than just a list of its words (which can be repeated without understanding the intention), and a text is more than just a list of the facts or individual ideas it contains. Fifty years ago, Joseph Novak and his colleagues at Cornell University developed a strategy called concept mapping that reveals the architecture of complex ideas by providing a visual representation of their relationships. Ideally, a text should reflect a mental architecture, and concept maps can be used both to plan how information should be presented and to determine whether it is understood.
The strategy is extremely useful in teaching and learning, where the goal is usually not just to memorize facts – at least it shouldn’t be – but to link them together in meaningful structures and to other knowledge. Concept maps have been used to measure learning: a student draws a map of his knowledge of something before a lesson or learning activity, then another afterward; comparing the two should reveal a change – hopefully in the direction of the map the teacher has in his head.
I drew extensively on concept maps during my analysis of scientists’ writing problems. One great advantage of this system is that it is not linear: it can display complex relationships such as hierarchies and patterns of ideas. While the concepts in our minds are certainly also arranged in very complex and dynamic patterns that we move through quite freely in thinking about something, we can’t see the whole structure all at once.
Concept maps give a scientist a way to analyze the content of what he wants to explain before he writes, and they are also a good way to visualize assumptions about how the audience probably has various ideas arranged in their heads, marking gaps that need to be filled and links that need to be made. They also provide a way to compare the way two people have their knowledge of a system or field organized, a way that is not restricted to a linear mode of transmission.
Maps show that the way information is arranged in a text is a layer of meaning that can generate ghosts of its own. Readers have to sort information into hierarchical structures to distinguish main points from details, and important information from “noise”. Writers have to rely on a number of cues, signal words and other devices to show readers how their maps should be organized.
As an exercise, I made a quick map of what I knew about gene expression – the general topic of the press release, which appears below. It is my own version – as nearly as I can represent their logical connections in my mind – and is far from complete:

I can’t “see” this entire map in my mind while thinking about the topic; putting it on paper not only allows me to see multiple connections, but also permits a manipulation of ideas in ways that I can’t in my head. For example, I can put my finger on any two spots (or throw darts at it and choose points by random) and ask, “Is there any biological connection between these two components or processes?” Since all of these components occur in a single cell, the processes they are involved in are coordinated with each other, and scientists have found many links between them in places they didn’t expect. I might also start at the top and work my way down while asking, “At what point in evolution did this process evolve?” The most fundamental parts of the system can be traced back to the last common ancestor of every organism alive today, but other parts were filled in only with the rise of animal life.
There are so many components and so many types of relationships that it would be impossible to impart the entire system in a single text (without writing an entire book). But what about the story from the press release in the previous section? In the map above I began highlighting elements that had to be mentioned, and then created a second map focused just on the content that had to be dealt with to tell that particular story. Here it is, with the main point of the story highlighted in orange:

If I’m writing a press release about this story, this is the map I hope readers will draw and remember after reading it. The map suggests ways to streamline the story, and each link represents a proposition or statement that needs to be stated in the story. This vastly simplifies my efforts to reduce a sprawling piece of science into a reasonable number of statements; now all I have to worry about is presenting them in an order that helps the reader build the whole structure.
There are a lot of tricks that can help in this process. One is to note that much of the language in the map derives from metaphors: transcription, binding, encoding. “Reading” doesn’t directly appear in this version of the chart, but it’s another concept that is useful in telling the story. I will devote a future chapter to the powerful ways metaphors can be used to communicate complex patterns of ideas. They can also be used as tools to investigate and manipulate scientific models – another chapter.
In this story the central metaphor has to do with texts: reading and transcribing. There are three basic components: DNA, the transcription machinery, and the RNAs it produces. There is a notion of motion: forward and backward reading. The other concept that needs to be introduced is binding – the fact that transcription begins when a machine binds to DNA (at a specific location called a promoter sequence). With just these concepts I can tell the entire story, a much simpler one with no red herrings and no wandering off into extraneous points.
* * * * *
4. Ghosts underlying a lack of clarity: What does “robustness” mean?
A friend of mine runs a laboratory devoted to understanding the processes that guide embryonic development in animals. He frequently sends me papers to edit and comment on before submitting them to journals. One of his postdocs recently sent me a paper with a passage that beautifully displays the power of the concept of ghosts in understanding and resolving a communication problem. It does something else as well: it shows how chasing ghosts can help scientists understand the cognitive structure of their own models. I think that is an essential step in the scientific process because it can help scientists generate new types of questions and develop new perspectives on the systems they are studying.
At one point in the text the scientist seemed to be using the term “robustness” in an unusual way. In everyday English, “robust” usually means “sturdy”, capable of withstanding some sort of disturbance, able to survive hardship, etc. In science it’s meaning is a little different, which will be discussed after the example.
I cite part of the passage here, mainly to provide a context for readers who are scientists:
Developmental advantages could arise if gastrulation became more robust, i.e., more reproducible in embryo-to embryo comparisons, or if it became more efficient and saved time.
We next asked whether this reduction was due to decreased variation within individual embryos and could be explained exclusively by the increase in the coordination of gastrulation that we had observed, or whether variability was additionally reduced between embryos of the same species, thus indicating higher reproducibility and an increase in developmental robustness. We found that within-embryo as well as between-embryo variation was decreased significantly following expression of the two molecules. The decrease in between-embryo variation suggests that, in the context of mesoderm internalization, the evolutionary gain in the expression of the two molecules contributed to an increase in developmental robustness.
I had always associated the term “robustness” in biology with something else: the ability of a process or system to continue despite some type of interference. This happens in situations where systems have a “backup plan:” a second way of accomplishing some task in case the usual process fails. Robustness can be important in development: an organism may be able to compensate for a defect in a gene by calling on another molecule to take over its functions. The same thing occurs during evolution: changes in a species’ genome alter basic processes all the time; organisms remain viable as long as they can somehow compensate, and this “robustness” provides raw material for diversity and natural selection.
In this text Steffen seemed to be drawing on a different definition of robustness. Somehow he was linking the term to changes in the amount of variation that organisms exhibited over time. When I talked to him later, he explained what he had meant.
Scientists have observed that embryos (and cells) go through phases of development in which they become very similar. Apparently at these phases their survival depends on adhering to very strict “rules” about the molecules they express, their structure, and so on. This is true about different types of cells (there are phases of the cell cycle where different stem cells look almost identical, and at others various stem cells look different); it’s also true of different individuals of a species, and it even holds for different species that have descended from the same ancestor. Their embryos go through phases in which they look highly similar.
Steffen had mostly worked in developmental biology, and he had developed a different interpretation of the term. He thought of “robustness” as a reduction in variation that resembles a bottleneck: if you plot the amount of variation over time, embryos of the same species start out with lots of differences that get reduced and converge at certain points of development. Later they spread out and exhibit more differences again. The metaphor is the image of a bottleneck that organisms have to squeeze through – otherwise they die.
As we talked about this we realized that in a way, these two versions of robustness may simply be different angles on the same thing. A “backup system” implies that a process in an organism may take different routes – but it’s still trying to get to the same endpoint. Imagine three paths through a forest that start at the same place, drift away from each other, and eventually meet again somewhere farther along in the forest. The point where they cross is the bottleneck that all hikers have to go through. Before they get there, however, you’ll find them scattered all through the forest.
This case is interesting because it points out that even within science, scientists may relate concepts to different models and think of them in different ways. Our distinct concepts of robustness weren’t the product of a deliberate decision to enhance or change a common definition – we had simply encountered the term in different contexts, linked it to other ideas in different ways, and used it in discussions without noticing any discrepancy. That might have gone on for a long time if Steffen hadn’t used the word in a specific context that I found unusual.
The differences were interesting and productive, because it gave each of us a wider view of a phenomenon that is widely observed but not very well understood. Our slightly different takes on it might make us look at cells or organisms in distinct ways and encourage us to perform different types of experiments. They might help us answer a question, or interpret data in a slightly different way in the future. Such disagreements bring science farther along.
This case was also interesting because it pointed out that even though robustness is an important concept, neither of us had been taught it in a structured way – or been explicitly shown how to think of it in contexts like models of embryonic development or evolution. There is, in fact, a great debate going on in biology right now about how robustness should be defined, how it arises, and what it means. Entire research projects are being set up to pursue these questions.
As I followed up on this, I was amazed to learn that very few science students, in fact, are taught about models in any structured way – despite the fact that everything they are doing is entirely shaped by the many models that impinge on the systems they are studying. In writing, their claims about systems have to adhere to many models: physical and chemical laws, the principles of evolution, models of cells and species and processes and so on. They have to link all of these things together in their heads and produce a text that confirms to rules from very different types of scientific “grammar”. Since they haven’t been taught that this is an important goal, they don’t even think of their projects this way, leading to disorganized thinking and writing.
This entire line of thought arose from the use of a single term in a single paper. The process of scrutinizing a text and exposing its ghosts is so important because it reveals profound aspects of how scientists think about things and how they have organized their knowledge that are otherwise likely to go unnoticed – or simply cause misunderstandings.
It’s also a way of coming up with interesting new questions. When we think about things, our minds skip logical steps and leap over fuzzy ideas in ways that hide gaps and smooth over rough places. These are ghosts that reside in our own thought processes, and they are devilishly hard to find without tricks to flush them into the open. One is writing, which requires deconstructing those ideas into a linear form so that they can be retraced, step by step, to look for such problems.
I continually find that unclear terms or phrases in students’ texts mean one of three important things:
- The writer doesn’t have a clear idea of a concept and its relationship to other ideas.
- The writer hasn’t spent time thinking about what the audience might know about a concept, how they are likely to link it to other ideas, and how they will probably interpret what he has written.
- Scientists in general don’t have a clear understanding of a concept, and there is something illogical or inconsistent about the way a writer is trying to apply it. That attempt may expose some fundamental problem with the concept that might even be useful in clarifying it.
All of these cases show how important the process of writing can be in building a scientist’s cognitive laboratory and testing its structure. The third point is the most interesting, because it demonstrates that the process of writing and reflection can raise new scientific questions that may have been hidden by our own ghosts.
* * * * *
5. Ghosts in the hidden structural function of a text: building mental lists
Often the function of a passage in a scientific text is to get a reader to create a list of the steps in a process, or fill out a mental table in which different conditions are systematically compared. The writer needs to realize that the information in his head is structured this way, needs to consider how useful it will be for the reader to adopt that structure, and then has to arrange the text in the way that get it across as clearly as possible. It’s easiest if you announce the structure before giving the audience the bits that will be filled into it. For example: “The NFκB signaling pathway in cells consists of a sequence of steps that begin when a signal called TNFα…” Or, “In this experiment we compared four lines of mice under three conditions…”
Building the structure while filling in the content is more difficult, or more complicated than necessary, and may lead to complete confusion. And assembling the list or table properly will require an extra effort by readers to put together a puzzle – why make them work so hard, especially when they may not have the time, or you’ll want their brains free to really concentrate on the important stuff? These structures are often crucial to an argument: in a list you need to try to build a complete, gapless chain to prove that a sequence of events really happens the way you claim. We use tables also to show completeness, for example by comparing the outcomes of different experimental conditions to controls – any box left blank will be pounced on by a reviewer, and may lead to doubt or skepticism about your conclusions. Or the reader will simply be confused.
It’s strange how often such textual schemes become opaque simply because the author hasn’t realized that he’s trying to convey information with a very simple structure. Sometimes there are, of course, reasons to present steps differently than their sequence in time, but this ought to be done thoughtfully, and only if there’s a good reason.
Here is an example from the first draft of a recent paper by a friend. The topic is a biochemical signaling cascade in cells which has potent effects; if the cell loses control of it, the result may be cancer. The intended audience for the paper is diverse: it would be of interest to biochemists familiar with the pathway, to cancer researchers, to other groups that use algorithms to model biological processes, etc.
The scientists developed a mathematical model of the signaling pathway. Their goal was to determine whether the system could be brought back under control by intervening at one specific step. Here’s the initial description of the pathway:
In canonical NF-κB signalling, transcriptional activity of the NF-κB transcription factor is regulated by the abundance of the NF-κB inhibitor IκB. TNFα stimulation reduces IκB concentrations via consecutive IκB phosphorylation by the IκB kinase (IKK) complex and subsequent IκB ubiquitination mediated by β-TrCP.
The list is not intended as a comprehensive overview of all of the steps, but rather to point out a major event in the control of the entire pathway. Still, presumably the author wants readers to sort the activity of the molecules into a sequence from the first thing to the last thing. That’s especially true because the theme of the project was to identify the most effective step – in this long chain – for interventions that would have the most impact on the last step. What’s interesting is that he has started rather toward the end and works his way forward and back in the sequence.
There is a rationale behind this, mainly having to do with tradition and the importance of one molecule. The system as a whole is called the “NF-κB pathway,” because NF-κB was identified early on and has very potent effects on cells; most of the other components were discovered later.
Later in the paper the same biochemical steps are described in another way:
This model quantitatively describes the molecular processes that transduce an extracellular TNF signal into a change of nuclear NF-κB concentration. The model accounts for transient TNF-dependent IKK activation, NF-κB-regulated target gene expression (cgen-mRNA), and the inhibitory action of IκB and A20 on NF-κB activation.
Here the description starts with the first event in the pathway, jumps to the crucial output at the very end, then covers some of the steps in the middle. In principle this is a reasonable strategy; providing the starting and ending points of the pathway introduces the “goal”; intermediary steps can be filled in later. Most readers of this paper will already know the players in the system – from other descriptions, often written in precisely these ways. But people who are less interested in this particular pathway and are more interested in the methodology, along with other types of readers whose attention you’d like to draw to this type of project, will have to slow down to assemble things into the proper order:
TNF signal – IKK – IKB – NF-κB – nuclear NF-κB – target genes
The paper has other points which will be challenging enough for readers, so any help the writer can provide will keep more of them engaged.
6. Ghosts in the hidden structural function of a text (B): building mental tables
Filling in tables is a second structure that underlies the function of a particular block of text, and the best example of confusion caused by this hidden pattern comes from a published article I often use in teaching. The original paper is full of ghosts and language that is almost impenetrable. Those two things go hand-in-hand and here we’ll deconstruct the reasons why.
The paper is entitled, “Effects of thyroid hormone defciency on mice selected for increased and decreased body weight and fatness.” which already hints at a real problem with clarity that will run throughout. “Increased and decreased body weight and fatness” combines terms in a way that is ambiguous, to say the least. Things just get better with the first three sentences of the introduction:
Selected lines of mice provide a model for the analysis of the genetic basis of quantitative traits in animals. Whilst the responses of quantitative traits such as body size and fatness are likely to be dependent on changes at many loci, the contributions of particular candidate loci or metabolic or hormonal pathways can be investigated to find out whether they are responsible for a substantial part of the genetic change. Their contribution to genetic variation in the trait in the segregating base population from which the selected lines were taken can then be assessed, with the aim of understanding the basis of quantitative genetic variation.
Those three sentences are the sum total of what readers get in terms of an answer to the first question everyone has when starting a paper: “What is this about?” The answer certainly can be recovered from the text, and it is an accurate statement of a general problem, but most scientists have to bang their heads on it for a while to get the point. One problem with this is that nowadays, nobody has the time. Even “way back” in 1998, when this paper was published, what scientist or journal editor could take off a whole afternoon to ponder such a paper? Today the average researcher has to read so much that this type of writing is almost criminal.
These three sentences are a gem worth considering, and we’ll come back to them in the next section. But the point for now comes in the four sentences that directly follow:
In this laboratory we have lines of mice that have been selected divergently from the same base population for body weight and for fatness for about 50 generations. At the age of selection, 10 weeks, the high body weight line is three times as heavy as the low body weight line, but these lines differ little in proportion of fat. The fat line has 5- to 6-fold higher fat percentage of body weight than the lean line at an age of 14 weeks, this ratio increasing with age, but the lines differ little in fat-free body weight (Hastings et al., 1991 ). These lines therefore provide very suitable material for experiments to investigate the role of candidate genes and pathways.
Here is the classic textual table, to be filled out in rows and columns, and the first question I ask students is, “How many columns will the table need?” In other words, how many lines of mice is the laboratory investigating? Even simpler yet, “With the arrival of each new litter of mice, how many groups did the lab sort pups into?”
The answer is so central to the methodology that at least this one point needs to be clear. But it isn’t; students who have had 15 minutes to read just seven sentences give different answers – rarely the right one. One way to resolve the problem would simply be to print such a table next to the text, but the authors don’t. Later, when they finally get around to it, we discover that whatever number of mouse lines they are working with are further subdivided, into male and female animals.
It’s interesting that the problem in the language describing the “table” is the same as the problem in the title – an issue with the way terms are grouped or combined. In this case it’s the sentence structure that makes things confusing, plus a connection that the audience will probably make that the authors don’t. The issue is this:
While we usually associate body weight with fatness, they are actually two different things that are somewhat independent of each other. An animal can be heavy without having a lot of body fat. And an animal with a high body fat content isn’t necessarily the one that weighs the most. So these are separate categories in the study, and the lab is concerned with the extremes of both traits: high weight and low weight, high body fat and low body fat.
Again, this can be recovered from the title and this second group of sentences, but it’s just too hard. In any case it means that the lab is working with four groups of mice plus the control (a “nonselected” base population from which all the subgroups are derived):
| Mouse Strain | + body weight | – body weight | + fat content | – fat content | Control |
| Value weight | 3x | 1 | about the same | ? | |
| Value fat | about the same | 5-6x | 1 | ? | |
In the paragraph above describing the results, the authors state:
At the age of selection, 10 weeks, the high body weight line is three times as heavy as the low body weight line, but these lines differ little in proportion of fat. The fat line has 5- to 6-fold higher fat percentage of body weight than the lean line at an age of 14 weeks, this ratio increasing with age, but the lines differ little in fat-free body weight.
Now that we see the table, two things become clear: the values for the mice are relative to each other, rather than objective measurements of the weights and percentages of body fat, and no values are given for the controls. This is covered later in the paper, and at that point a figure is provided (see below). Here in the opening of the text, the authors are trying only to emphasize the pretty dramatic differences that their process of selection creates between the mice over 50 generations. That’s a valid point to make this early in the paper – but only if the procedure and the groups are clear.
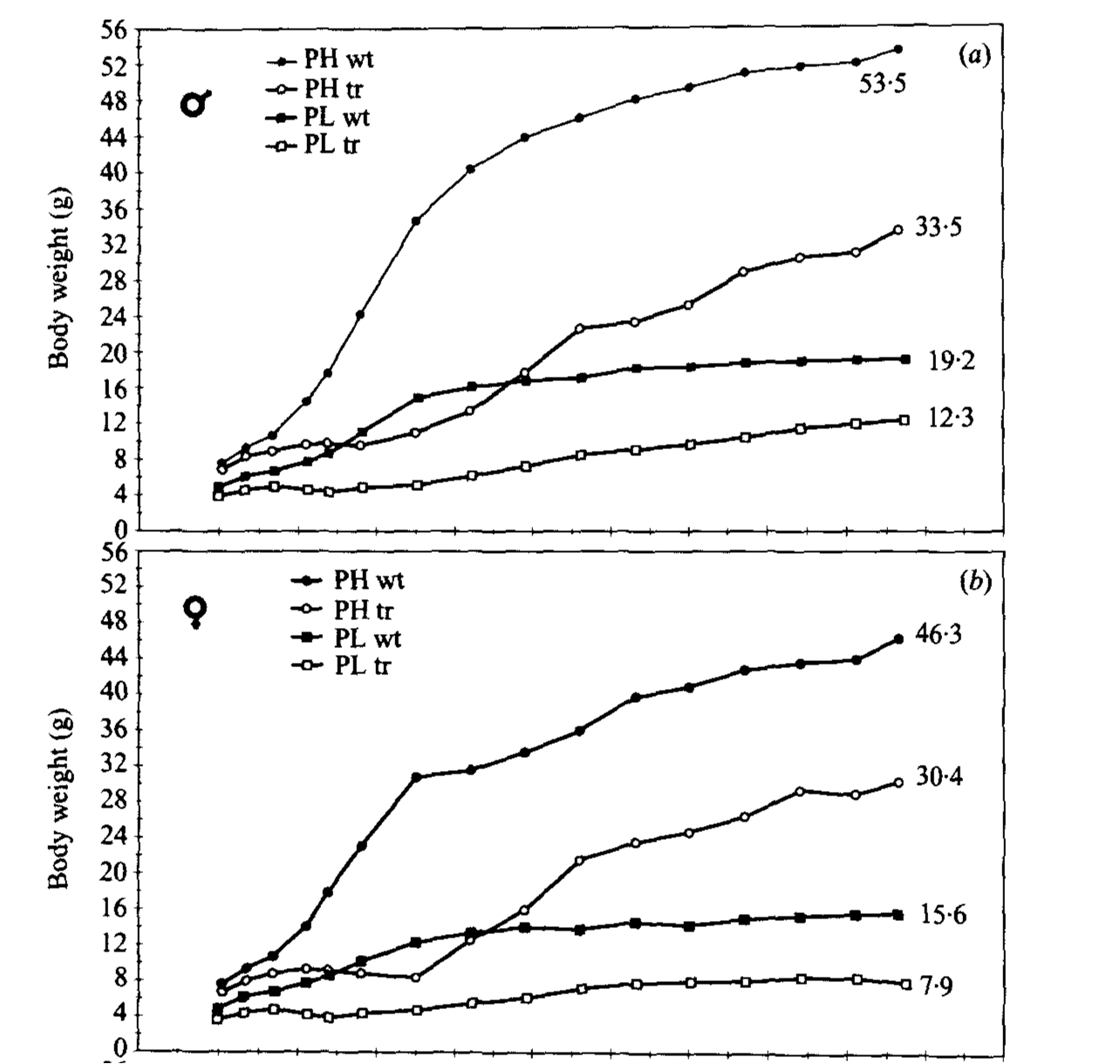
An example of one of the charts published in the paper, comparing body weights (y axis) of the four selected strains (but not the control!) over time (x axis, each hash mark represents one day). Top: males; bottom: females
I honestly believe that the authors had no idea how confusing these sentences are. They had the categories of their animals firmly in mind – you’d be dreaming about them after sorting mice for 50 generations – but chose language that increased the number of ghosts, because of a normal association people make between high weight and fatness, and between low weight and leanness. That association is so predictable that I’m sure members of the lab have to explain it all the time.
When a strong association in the audience’s minds needs to be dissolved or subdivided to transmit meaning, the writer has to be exceptionally clear. Here, rather than spending a few more sentences setting up the structure of the information they were about to give, they simply launched into it. The ghosts arose from a mismatch in the way the scientists thought about a problem and the way most readers normally think of it, combined with a structural ghost: the rhetorical act the reader has to perform is to fill in a mental table.
That leaves the biggest ghost behind this study: What model are the scientists trying to test, enhance, or refute with this work? The key is in the first block of text above – but to understand what they mean, you have to identify the model. And know a bit about its history.
* * * * *
7. Ghosts in a very high theoretical dimension
What does the paper described in the previous section mean? In other words, what scientific question motivated the project, and why on Earth would anyone go to all of this work in the first place? A lot of work it was indeed, breeding mice for 50 generations and tracking five groups! It should be obvious by now that these answers ought to be sought in the principal models that the work addresses. Here I have highlighted words that provide clues:
Selected lines of mice provide a model for the analysis of the genetic basis of quantitative traits in animals. Whilst the responses of quantitative traits such as body size and fatness are likely to be dependent on changes at many loci, the contributions of particular candidate loci or metabolic or hormonal pathways can be investigated to find out whether they are responsible for a substantial part of the genetic change. Their contribution to genetic variation in the trait in the segregating base population from which the selected lines were taken can then be assessed, with the aim of understanding the basis of quantitative genetic variation.
The word selection is a powerful one in science, because it hints back at Darwin’s concept of natural selection: one of the three pillars on which evolutionary theory is built. “Genetic basis” refers to the connection between the variations in genes found in different individuals of a species and the ways their bodies acquire distinct features, or traits, as they develop. This study is examining two specific quantitative traits – the weight of an animal and the fat content of its tissues. They are called quantitative because they can be measured using a scale or some other objective method.
This paper is talking about an artificial selection of animals in the laboratory rather than natural selection; here it’s the scientists that are doing the selection, by controlling which animals breed with each other, rather than letting nature take its course. Each generation they selected the males and females that weighed the most from a litter and bred them, the males and females that weighed the least, and so on.
One reason to study variation is to determine the connection between specific forms of genes and traits like weight. Finding such associations can help assess a person’s risk of a health problem, based on the recipes of their genes. But there’s another point to this paper: in a sense, the scientists are trying to create a laboratory model of the way natural selection works.
Nature might also “select” mice for these features. Depending on the predators that are around, and the climate and other enviromental conditions, under certain circumstances it might be an advantage for a mouse to weigh a lot, or very little; a high amount of body fat is useful for some things and a low level for others. That can play a role in evolution if certain other conditions are met: the variation in a trait has to be at least partly hereditary rather than purely behavioral; in other words, an animal has to pass its development of a high percentage of body fat to its offspring. Secondly, the trait has to contribute to the animal’s reproduction, maybe by helping it survive long enough to do so. Third, the advantage has to be maintained over a very, very long period of time. Finally, groups with different variants of genes may become separated from each other in environments that benefit different traits. If they are unable to mate with each other over an extremely long period, probably at least thousands of generations, this can lead to distinct species.
We have never been able to observe a species that long. We can watch a sort of micro-selection, which favors certain traits over a short period and alters the balance of gene variants in a population. But this doesn’t answer questions about the types of changes that permit an animal to develop the same type of body plan over many generations, or how many different genes might contribute to that plan, or at what point that process leads to new species.
Most evolutionary changes start with a mutation or another change in the sequence of an animal’s DNA – but nature does not see or “read” a species’ genes when it “selects” animals. Selection happens at the level of the entire organism, and is probably based on quantitative traits that nature does, in a certain way, see. This is one of the main issues suggested in the introdution of the paper: by artificially and very rigidly breeding animals based on their traits, the scientists are exploring what selection does at the level of genes over as many generations as they can keep their lab running.
One thing that makes it difficult for scientists to understand that aspect of this paper is that generally, natural selection is a poorly understood concept. Another problem in catching the meaing, of course, is that they aren’t applying this concept of identifying the central question of a paper and understanding its relationship to models. Here that dimension is a ghost, and it is related to a very high level of theory that most projects don’t tackle.
Natural selection is like the “membrane” in the very first example in this paper: scientists are supposed to know evolutionary theory, so they may not mention it unless it is directly implicated in a piece of work. And evolution is incredibly pervasive – with footprints that can be detected in nearly every piece of work. Natural selection is everywhere and nowhere because scientists assume that everyone else understands it. And as a result, they may not aware how poorly understood it really is. I won’t go into detail here, because I have covered this in another paper, but I will provide some evidence for this claim that I collected while developing this model of communication.
For about a year, every time I gave a talk or course to a group of PhD students in molecular biology, I started by asking them to write down a brief definition of natural selection. Only a very small proportion turned in definitions that resembled Darwin’s, or the updated version that is usually considered today. The rest contained some significant error, left out a key point, or were far, far off the mark. Here are some fairly representative answers:
“If you don’t adapt too much, then new things emerge.”
“A competition between individuals, a kind of fight for rare goods, where the strongest ones win, and it doesn’t have to mean that the rest die. The weakest ones may be led by the strongest ones.”
“The biological process of reproducing efficient traits of living organisms.”
“Natural selection is the death of animals because of a useless adaption or not adapted enough to the enviroment. In modern human life natural selection is almost extinct.”
“Natural selection is a process based on a model which describes the dying, the living and the morphing over time of individual creatures.”
I was completely stunned that so few of the definitions (and none of those listed here) comes close to an adequate answer. In the early 20th century, biologist Theodosius Dobzahnsky wrote, “Nothing in biology makes sense except in the light of evolution.” From this I inferred that students working on a PhD ought to have fully mastered the theory. They do not, as the answers show; some of these ideas are so skewed that Darwin would probably roll over in his grave.
A final comment about this: many years ago I wrote a book about evolution that required a deep immersion into the theory, its origins, and the way it has been adapted through the influence of modern findings. As I began to explore the relationship between models and communication, I came across a number of assumptions about evolution that scientists made all the time, but in fact had never been tested. Because they were making this assumption, they were drawing conclusions about other things based on it.
I was able to phrase this assumption as a question, and my good friend Miguel Andrade decided it was interesting enough test in experiments. The results turned out to be important enough to merit a paper, which we published together in the journal Genomics Data in 2015. For someone who had never had a single university course in any natural science related to biology, it was a thrilling experience. And it was an important validation of the connection I saw between science and communication.
8. Ghosts in images
I had been working hard at my error analysis when I was invited to give a grant-writing seminar for the students in Jochen Wittbrodt’s department at the Center for Organismal Studies (COS) in Heidelberg. I was beginning to see the crucial need to link texts to models, but had not yet developed the concept of ghosts. We were at a retreat in Obersdorf, in a villa surrounded by snow, and the work had gone so well that on the last evening the students asked if we could have an extra session. I went in without a plan and the first thing that happened was the appearance of this image on the screen:

note: I have lost the reference for this image; I’d be grateful to anyone who could provide it. If it is under copyright, please inform me and I will replace it.
At that moment I suddenly noticed ghost after ghost, leaping out of the image, by seeing it in two ways at the same time: as a scientist would, and as someone who had no idea what it was supposed to represent – the way a painter might.
The way we scan an image or object is powerfully configured by the knowledge that we bring to it, and many more kinds of general knowledge about the way three-dimensional objects are typically represented on a two-dimensional surface. We begin learning these conventions as children; they infuse visual media all around us. It’s not clear whether people from a culture without many images would see the image the same way.
We’ll start with the general aspects:
- Differences in color and shading create an illusion of depth (3 dimensions) by implying that some parts of the image are closer to the viewer (cultural learning)
- Colors represent distinct objects: the rust-colored areas connect the parts of one object, and the blue to another. The greenish-blue spiral woven around them represents yet another object. The image hints at two more objects: yellow and pink, suggested by the square-like structure that forms from the pieces sticking out beyond the borders of the circle.
- Lacking additional information, the back side is probably symmetrical to the front side.
When most scientists see this image, they can usually decipher it even though they may never have seen this type of image of it. They recognize:
- The scale of the object (at the molecular level of proteins)
- The double-helix structure of the spiral is DNA.
- The colored fields in the center represent a typical way of displaying functional regions of proteins; this type of image is called a ribbon diagram. The smaller spirals within them are a common depiction of a protein structure called an alpha helix.
- The fainter clumped forms in the background are another way of depicting proteins, basically by presenting the shapes of their surfaces.
- They will assume that the colors mark either distinct proteins or protein modules called domains.
- The DNA is apparently wrapped almost twice around a circular cluster of four proteins. If you assume that the back side also has a near symmetry, this implies that the whole “complex” has eight molecules. At that point the object becomes identifiable as a nucleosome: a spool-like assembly of proteins in the cell nucleus that helps organize DNA. Nucleosomes consist of eight histone proteins.
- The knob-like structures extending outside the circle represent the starting points of long, string-like structures called histone tails, which play a crucial role in switching genes on or off.
A nucleosome and this image also form a model: an archetypical representation of a structure involving eight proteins and DNA, with specific functions in the organization of genetic material in the nucleus.
From a text that describes a nucleosome, scientists build mental images of it which they can use to identify such a cartoon image. Because of a fundamental principle in molecular biology that the physical form and chemistry of a molecule determine its functions, such images play a crucial role in science. It is interesting that such images are rarely complete and usually have to be made by analogy to other molecules. In other words, a nucleosome such as the object in the image cannot be directly visualized; it has to be constructed through an imaginative process based on data, but extensively drawing on knowledge of many other models.
This means that the process of creating an image, like that of writing a text, generates a dialog that can be used to explore models and find gaps that have yet to be resolved. In other words, representations of scientific concepts provide a mode of exploring biological systems and generating new scientific questions.
* * * * *
9. Ghosts in descriptions of mental images
Just as parts of texts aim to help the reader complete a sequence or table in their heads, descriptions sometimes seek to convey a visual impression of an image that the reader needs to “see” to grasp its meaning. For this to be successful, the writer must carry out an exact “inner visualization” of its structure and mention all of the important points.
A scientist asked me to help her with a paper that illustrates this point and shows that extreme care is needed in constructing the image. Missing a single important connection – or presenting information in a confusing order – can disrupt the entire process.
Warning: this example is intended mainly for scientists, but I’ll do my best to set up the situation by referring to a few models. First, the author is describing a “molecular machine” composed of several proteins which come together in a step-wise series of events in the cell. The machine plays an important role in cells because it breaks down RNA molecules before they can be translated into proteins. This lowers the amount of the protein that the cell makes, giving it control over the processes in which it is involved. It’s a bit like keeping keeping your guests from drinking too much beer by breaking some of the bottles. The technical name for this process is miRNA silencing.
The bottle-breaking machine is composed of proteins called AGO, TNRC6, and CCR4-NOT. The cell has to assemble this machine, which means it has to attach the proteins to each other in the proper order and in the right positions. Instead of screws or bolts, the components are attached through chemical sequences on the molecules that act like patches of chemical “Velcro”. In this case the type of Velcro that is used is called a “W motif.”
In a lot of cases scientists don’t have a complete parts list for cellular machines, and the miR silencing machine probably has several components that scientists haven’t found yet. The student was trying to detect them using a method called mass spectrometry. Sometimes when she analyzed the components she found a molecule called AP2A attached to the machine.
AP2A is normally found on the surfaces of tiny, bubble-like compartments called clathrin-coated vesicles are made by pinching off a bit of the outer cell membrane and drawing it inside – think of the way a clown pinches and twists a balloon to make the form of the animal. The discovery suggested that sometimes one of these bubbles becomes attached to the machine. In this short text the author wonders what influence that might have on the construction of the machine and its functions. Here is an extract from her text, which I have slightly edited:
TNRC6 and AGO proteins are key players of microRNA silencing in animals. Short W-motifs dispersed throughout TNRC6 proteins recruit CCR4-NOT molecules, which promote the decay of target mRNAs. Here, I used mass spectrometry techniques to detect other molecules that might be recruited to TNRC6C proteins via W-motifs. Besides known interactors, such as subunits of the CCR4-NOT complex, I identified several components of clathrin-coated vesicles (CCVs) and other molecules as binding partners. One of these was AP2A.
I further showed that TNRC6 and AGO localize on CCVs via W motifs. When I lowered the amount of AP2A in cells, this caused a higher breakdown of RNAs, suggesting CCVs oppose miRNA silencing. Lowering the amount of CCR4-NOT increased TNRC6 interactions with AP2A. However, CCR4-NOT binding did not change when I lowered AP2A, arguing against competition of the two molecules in miRNA silencing.
Her point is that TNRC6 has a limited number of “velcro” W motifs on its surface, so if AP2A binds a bubble to the machine, CCR4-NOT may not be able to attach itself and the machine couldn’t be built in the proper way. One experiment described in the second paragraph suggested that this seemed to be the case. But another implied that it wasn’t.
I think the only way a reader will understand this problem is to see the parts of the machine in his mind – especially the order in which the pieces are attached, and where they lie in relationship to each other. In other words, the reader needs a very explicit “assembly manual” like those that come with IKEA furniture. But the author has left out some important cues about the order and position of some of the pieces. In fact, very subtly she has sent the reader astray for an understandable reason: her work is focused on TNRC6. Because it’s the center of her attention, it is shifted to places in the text that are slightly misleading. And the result is exactly the same as when a step is left out of the IKEA instructions, or you can’t clearly match the pieces on the diagram to those you find in the box.
Here the problem boils down to this: the first molecule she mentions is TNRC6, while it would be better to start with AGO. AGO is attached to the RNA that needs to be broken apart, TNRC6 is stacked on top of it in a second step, and CCR4-NOT is the top “pancake” on this stack. At the beginning of the piece she told us that TNRC6 has W motifs – Velcro – that it uses to attach itself to other pieces of the machine. We only find out later that AGO also has W motifs. We don’t know if that is strictly necessary, depending on how well the metaphor works – with “Velcro”, the patches on the two sides are different.
Do W motifs always attach to each other – in other words, do both molecules have to have them to stick? The text doesn’t tell us. This is crucial to understanding the issue with CCR4-NOT in the last paragraph. AP2A blocks something in the construction of the machine, but where? Does it block AGO’s binding to TNRC6, by occupying sites that need to be free for the two molecules to link? In other words, does it interject itself between the bottom two pancakes on the stack, or the top two? The text doesn’t make this clear. If all four molecules need W motifs to bind, the scientific problem is different than if only TNRC6 (and possibly AGO) has them.
I wondered if I could pinpoint the problem in a concept map. I tried to make one, with a few guesses about what she meant. When we met I showed it to her. She glanced at it very quickly. I hadn’t even explained to her what type of map was, or talked her through it, when she put her finger on the lower right-hand side and said, “I would have done this differently.”

I laughed and told her I probably would, too, if she could clarify a couple of points for me. She did, answering the questions I had at the time, and then I drew another map:
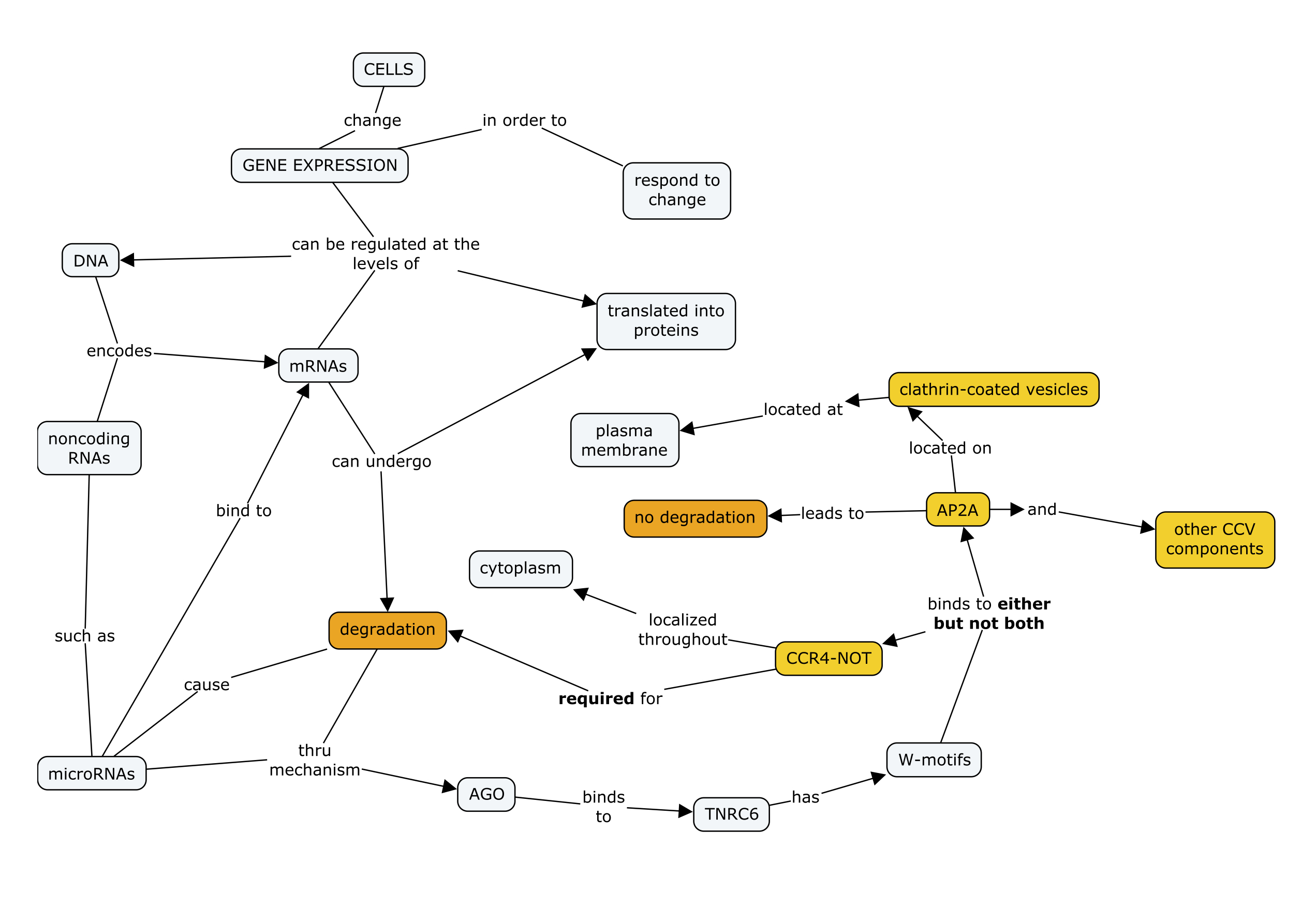
A scheme of the AGO-TNRC6-CCR-NOT complex. If AP2A binds to TNRC6, CCR-NOT apparently can’t.
Obviously all of these problems can be resolved by including a small diagram of the machine. But that’s like giving someone instructions to get to your house, and then telling them at the end they should just buy a map. And it’s not strictly necessary – if an author realizes that the reader is trying to construct a visual model of the machine in his mind. Simply thinking of the problem that way will help immensely. But it demands that the author herself see the model very clearly, describe it, and then scrutinize the description for ambiguity or points that might be confusing.
The key point is this: the process of communication requires that a writer take a fresh look at a problem and try to examine his own thoughts – and the language in which he expresses them – from another perspective. He needs to develop a model of what a reader already knows and can see so that he knows what he needs to say to change that model so that it fits what is in the scientist’s head. If you can’t do that, readers – such as the people who review papers for journals – won’t get the point, or agree with your conclusions.
Clear, effective communication simply can’t work without going through this process. And doing so is crucial to doing better science because when a scientist has been focused on a problem for a very long time, he develops a mental shorthand in which the gaps in his own knowledge become invisible ghosts. Those gaps can impede progress in science because they represent parts of a model that are not yet clear, but which the scientist is not addressing because he simply no longer sees them.
The invisibility of models also becomes a problem when a scientist reads another piece of research. A person can become so reliant on his own models that he tries to simply asssimilate every new piece of information into it – whether the data comes from his own experiments or someone else’s. When something doesn’t fit, it is easy to disregard, ignore, disbelieve, or simply not see it. The challenge is to be open to cases where the problem is the model, and not the data, and realize that the model has to undergo a process of accommodation. Most truly impressive, remarkable pieces of science involve such an accommodation. Achieving them usually requires exposing ghosts, and the easiest way to do so is by trying to communicate science to others.
Because models often lurk in our minds as ghosts, scientists develop an “instinct for the experiment” that rises from patterns that have been integrated, rendered abstract and metaphorical in the inner cognitive laboratory, and do not hesitate to cross into other types of understanding. Since scientists can only construct the same models to the extent that they can agree on meaning, there is a zone of variation in their cognitive models that will remain individual, and clashes between very subtle versions may be the key to progress. So this instinct is an entirely valid method of approaching a question. When we articulate a model, we are not capturing its essence, but translating it into a version that we are ready to understand at that moment.
So making sense of a result is best undertaken with the fullest possible awareness of the ghosts and models that shape in the experiment. Because whether a scientist realizes it or not, an experiment tests every level of all of them. There are always different ways to interpret the results; the question is, do we understand what they are trying to communicate to us? Every dialogue is susceptible to ghosts, even the ones we carry out with ourselves. There is a method to exposing many of them, and it is crucial in capturing meaning in a dialogue: whether with another scientist, our own assumptions, or the system to which we have posed a question. It might have understood the question in a different way than we intended, and so the answer it gives may be richer in meaning than we are prepared for.
A few references
Bünger L, Wallace H, Bishop JO, Hastings IM, Hill WG. Effects of thyroid hormone deficiency on mice selected for increased and decreased body weight and fatness. Genet Res. 1998 Aug;72(1):39-53.
Shih J, Hodge R, Andrade-Navarro MA. Comparison of inter- and intraspecies variation in humans and fruit flies. Genom Data. 2014 Nov 22;3:49-54. doi: 10.1016/j.gdata.2014.11.010. eCollection 2015 Mar.
Novak JD. The promise of new ideas and new technology for improving teaching and learning. Cell Biol Educ. 2003 Summer;2(2):122-32.
The concept-mapping software used in this program was created by Joseph Novak and his colleagues, and versions for PCs, Macs and other platforms can be downloaded for free from the website of the Florida Institute for Human & Machine Cognition. https://cmap.ihmc.us


